

CPU
Le CPU Central Processing Unit parfois aussi appelé processeur ou microprocesseur est le cerveau du PC. C'est d'ailleurs le composant le plus cher. Il coûte grosso modo le double du prix de la carte mère.
Sa puissance dépend
- du nombre de cœurs du processeur,
- de la taille de sa mémoire cache
- de l'architecture du processeur
- et de sa fréquence
La fréquence du CPU s'exprime en MHz ou en GHz. C'est une valeur à laquelle les utilisateurs attachent le plus d'importance mais d'autres paramètres en déterminent les performances.
L'efficacité du CPU dépend aussi de son architecture interne. Alors qu'il fallait dans les premiers PC environ 12 cycles pour exécuter une instruction, les processeurs actuels traitent plusieurs instructions par cycle. Ces traitements se font en parallèle grâce notamment à la technique du double pipeline d'instructions, ce qui leur permet d'effectuer deux ou trois instructions par cycle. L'hyperthreading est une autre technique encore pour faire le traitement simultané de plusieurs flux d'instructions, les "threads".
Le rôle de la mémoire cache est d'autant plus important que la vitesse du CPU est élevée par rapport à celle de la mémoire centrale. Cet écart entre la vitesse du processeur et celle des RAM ne cesse d'augmenter car l'évolution des CPU est bien plus rapide que celle des mémoires. La mémoire cache coûte cher. Sa taille explique souvent la différence de prix entre les processeurs.
L'augmentation des fréquences a atteint des limites aux environs de 4 GHz. La seule façon d'augmenter encore les performances est maintenant de multiplier Les coeurs sur la même puce.
Description
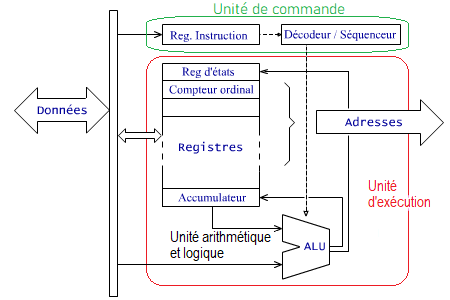
Nous avons vu que du CPU partent des ensembles de fils appelés "bus" auxquels sont connectés les autres composants du système.
Le CPU est constitué essentiellement de trois parties :
- L' unité de commande qui cherche les instructions en mémoire, les décode et coordonne le reste du processeur pour les exécuter. Une unité de commande élémentaire se compose essentiellement d'un registre d'instruction et d'une unité "décodeur / séquenceur"
- L' unité Arithmétique et Logique ( ALU) exécute les instructions arithmétiques et logiques demandées par l'unité de commande. Les instructions peuvent porter sur un ou plusieurs opérandes. La vitesse d'exécution est optimale quand les opérandes se situent dans les registres plutôt que dans la mémoire externe au processeur.
- Les registres sont des cellules mémoire internes au CPU. Ils sont peu nombreux mais d'accès très rapide. Ils servent à stocker des variables, les résultats intermédiaires d'opérations (arithmétiques ou logiques) ou encore des informations de contrôle du processeur.
La structure des registres varie d'un processeur à l'autre. C'est ce qui fait que chaque type de CPU a un jeu d'instruction qui lui est propre. Leurs fonctions de base sont néanmoins semblables et tous les processeurs possèdent en gros les mêmes catégories de registres :
- L'accumulateur est principalement destiné à contenir les données qui doivent être traitées par l'ALU.
- Les registres généraux servent au stockage de données temporaires et de résultats intermédiaires
- Les registres d'adresses servent à confectionner des adresses de données particulières. Ce sont, par exemples, les registres de base et d'index qui permettent entre autre d'organiser les données en mémoire comme des tables indicées.
- Le registre d'instruction contient le code de l'instruction qui est traitée par le décodeur / séquenceur.
- Le compteur ordinal ou program counter contient l'adresse de la prochaine instruction à exécuter. En principe, ce registre ne cesse de compter. Il génère les adresses des instructions à exécuter les unes à la suite des autres. Certaines instructions demandent quelquefois de changer le contenu du compteur ordinal pour faire une rupture de séquence c'est à dire un saut ailleurs dans le programme.
- Le registre d'état appelé parfois registre de condition contient des indicateurs appelés flags (drapeaux) et dont les valeurs (0 ou 1) varient en fonction des résultats des opérations arithmétiques et logiques. Ces états sont utilisés par les instructions des sauts conditionnels.
- Le pointeur de pile ou stack pointer gère certaines données en mémoire en les organisant sous forme de piles.
Principe de fonctionnement du CPU
Le contenu du compteur de programme est déposé sur le bus d'adressage pour y rechercher une instruction en code machine. Le bus de contrôle produit un signal de lecture et la mémoire qui est sélectionnée par l'adresse, renvoie le code de l'instruction au processeur via le bus des données.
Une fois que l'instruction aboutit dans le registre d'instruction, l'unité de commande du processeur la décode et produit la séquence appropriée de signaux internes et externes qui coordonnent son exécution. Une instruction comporte une série de tâches élémentatires. Elles sont cadencées par les cycles d'horloge.
Fonctionnement du processeur - Simulation en langage Assembleur
|
Le simulateur que voici montre ce qu’est un processeur et sa programmation en langage machine.
Le CPU imaginé ici est simplifié à l’extrême.
Le seul but est d’en faire découvrir le fonctionnement, pas d’en faire un outil de calcul.
Il permet tout au plus d'écrire et de simuler le fonctionnement des petits programmes de quelques instructions. Le simulateur est réalisé dans le classeur Excell que je vous invite à télecharger en cliquant sur l'image ci-contre ou sur ce lien : |
La programmation des microprocesseurs en langage assembleur ne se fait plus que de manière très exceptionnelle. Pour les PC, cela pouvait se faire facilement avec les outils que le DOS ou Windows jusqu’aux versions 98 et XP. Il y avait pour cela un utilitaire nommé DEBUG que Microsoft a maintenant retiré des nouvelles versions de Windows.
À présent, les commandes qui concernent le processeur et les périphériques doivent toutes passer par des requêtes au système d’exploitation. C’est lui seul, qui avec l’aide des pilotes de périphérique, gère la machine au niveau le plus proche du matériel.
L'intéret de la programmation en assembleur est essentiellement pédagogique.
Cela permet de se rendre compte des mécanismes internes du processeur.
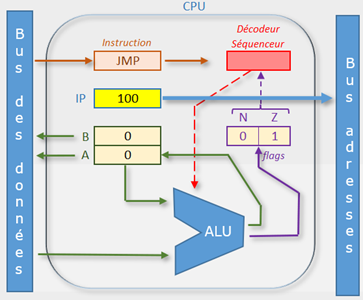
Le processeur
Le processeur de ce simulateur contient :
-
L’unité d’exécution composée de :
- L’unité arithmétique et logique (ALU).
- Des registres pour les variables et les résultats temporaires des calculs. (A et B)
- Un registre IP "Instruction Pointer" qui contient l’adresse de l’instruction à exécuter.
- Un registre d’état (les flags) dont les valeurs se positionnent en fonction des calculs faits.
-
L’unité de commande
- Un registre d’instruction qui reçoit le code de l’instruction à exécuter.
- Le décodeur séquenceur qui orchestre le fonctionnement du CPU.
Dans le cas de ce simulateur, le processeur est réduit au strict minimum :
- L’ALU ne fait pas d’opérations logiques.
- Elle se limite à faire des additions et des soustractions.
- Il n’y a que deux bits indicateurs : N pour indiquer les résultats négatifs et Z pour marquer les résultats nuls.
- Il n’y a que deux registres : A et B.
- Au lieu de faire un processeur 8, 16, 32 ou 64 bits, ce processeur didactique peut contenir de simples nombres entiers que l’on écrira en décimal pour ne pas compliquer la chose en binaire comme cela se passe pourtant dans la réalité.
La mémoire
Il faut se représenter la mémoire comme une suite de cases numérotées. Chaque case contient en principe un octet et a une adresse. Ici les cases peuvent contenir des nombres quelconques et même les mnémoniques du code d’assemblage.
La mémoire simulée ici est en deux parties : un composant occupant les adresses de 100 à 135 destiné à recevoir les instructions de vos essais de programmes et une RAM occupant les adresses de 200 à 235 destinée à simuler les données numériques que vont traiter vos programmes.
Jeu d'instructions
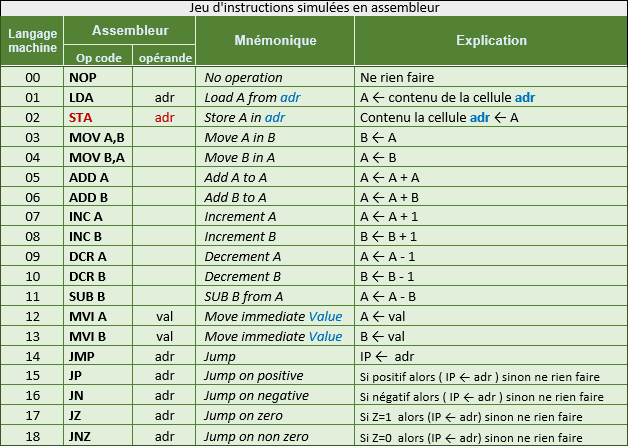
Chaque instruction est en principe écrite en binaire.
Le code machine de l’instruction "MVI A" serait 12.
Ici, pour que ce soit plus simple à utiliser, ce code sera de suite entré en mnémonique.
Les opérations commandées par ces instructions sont simulées à une exception près :
l’instruction STA adr qui est censée copier le contenu de l’accumulateur dans la mémoire ne peut pas être simulée.
Elle s’affiche en rouge pour rappeler cette limite de la simulation.
La simulation
Pour ce simulateur, le processeur débutera toujours l’exécution des programmes en commençant à l’adresse 100.
Le résultat de la simulation est une trace de l’exécution qui montre pour chaque étape l’instruction lue,
les effets sur les registres et sur les flags.
La feuille Excel est protégée. Les seules cellules où vous pouvez écrire sont les contenus des mémoires et du registre IP.
Exemple 0
Observons ce qui se trouve dans la première feuille : « Simulation Assembleur »
Encodage du programme
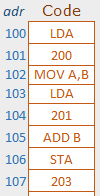
Écrire des instructions du programme dans l’espace mémoire prévu pour le code à partir de l’adresse 100.
Attention à entrer exactement les mnémoniques.
Le simulateur n’est pas capable de marquer les erreurs de syntaxe.
Il se perdra aussi si par exemple vous ajouter un caractère espace à la suite d’un mnémonique.
Certaines instructions nécessitent un «code opération» ou opcode et un opérande.
Exemples : LDA adr, MVI A valeur ou JMP adr. Ces instructions occupent 2 cellules mémoires.
Pour d’autres instructions, seul un opcode suffit.
C’est le cas par exemple des instructions d’incrémentation (+1) ou de décrémentation (-1)
Exécution
Le simulateur donne la trace de ce que serait l’exécution du programme
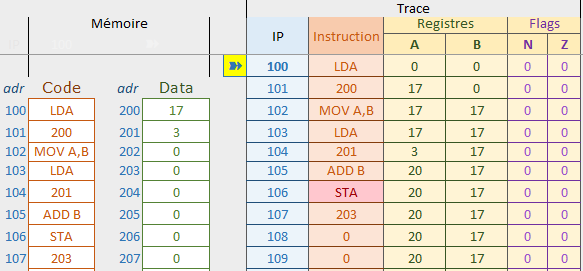
| IP=100 |
Le processeur commence par lire l’instruction à l’adresse 100. L’opcode LDA indique qu’il faut lire un octet en mémoire. |
| IP=101 | Le séquenceur va chercher dans l’octet suivant l’opérande qui représente l’adresse de la donnée à lire. Le registre A prend la valeur lue en 200. (17 dans notre exemple) |
| IP=102 | L’instruction MOV A,B demande la copie du contenu du registre A dans B. En effet, A doit être libéré pour pouvoir servir à la lecture suivante. |
| IP=103 | Commande de lecture LDA … |
| IP=104 |
Lecture à l’adresse 201 Le registre A reçoit le contenu de la cellule 201. (3 dans cet exemple) |
| IP=105 | L’instruction ADD B commande au processeur d’ajouter la valeur contenue dans B à celle du registre A. A vaut maintenant 20 (3+17) |
Suggestion : Changez les valeurs en 200 et 201 pour voir ce que cela donne comme résultat. Observez comment cela modifie les flags lorsque le résultat est nul ou négatif.
Exemple 1
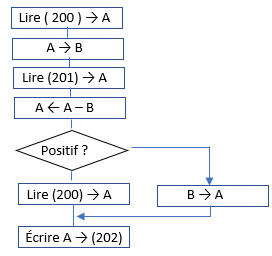
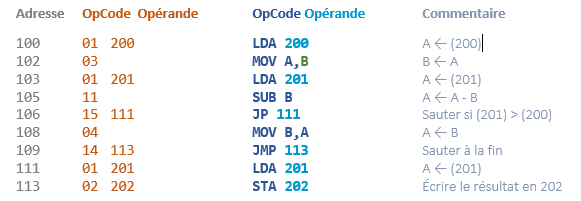
Écrire un petit programme qui compare les valeurs que contiennent les cellules 200 et 201. Le programme devra chercher la plus grande de ces valeurs qu’il est censé écrire dans la cellule 202.
Organigramme et code
Exemple 2
Ce petit bout de programme calcule une puissance de 2 en se servant du contenu de la cellule 200 comme exposant. Exemple 23 = 8
Cet exemple montre comment faire une boucle en assembleur.
Conclusion
Ce simulateur ne vous permettra pas de tester autre chose que de tout petits programmes.
J’espère qu’il pourra aider ceux que cela intéresse à imaginer comment fonctionne un processeur.
Parallélisation
Toutes les tâches qui constituent une instruction s'exécutent les unes à la suite des autres. L'exécution d'une instruction dure donc plusieurs cycles. Comme il n'est pas toujours possible d'augmenter la fréquence, la seule manière d'accroître le nombre d'instructions traitées en un temps donné est de chercher à en exécuter plusieurs simultanément. On y arrive en fractionnant les ressources du processeur, les données et/ou les processus. C'est ce qu'on appelle la parallélisation.
Pipelines d'instructions et architecture superscalaire
L'unité de commande élémentaire qui, dans les premiers microprocesseurs, contenait un registre d'instruction et
un décodeur/séquenceur, est remplacé depuis les processeurs de la troisième génération (386) par un ou des pipelines.
Dans le 486, le pipeline est unique et se compose de cinq unités fonctionnelles.
Elles "travaillent à la chaîne" pour effectuer simultanément les étapes successives de plusieurs instructions.

La première unité fonctionnelle du pipeline va chercher les instructions en mémoire et les range dans un tampon, la seconde unité décode l'instruction et ainsi de suite.
Globalement, il faut toujours autant de temps pour exécuter une instruction mais la vitesse d'exécution est multipliée par cinq puisque avec ce système les instructions suivantes sont entamées dès que possible, les instructions se font donc en parallèle.
Les premiers Pentium (cinquième génération) ont deux pipelines en parallèle ce qui leur permet d'accomplir deux instructions par cycle.
Dans les processeurs suivants, l'architecture "superscalaire" multiplie les chemins des instructions au niveau de certains étages du pipeline, les unités fonctionnelles d'exécutions ont alors recours à plusieurs Unité Arithmétiques et Logiques (ALU). Le processeur est dit superscalaire de rang "n" s'il possède n unités arithmétiques et logiques.
Le pipeline du 486 perdait de son efficacité lors des ruptures de séquences. Lors des sauts conditionnels, les instructions qui suivent le saut et dont le traitement a été entamé doivent parfois être abandonnées après l'évaluation du test. En cas d'erreur, la perte de temps est d'autant plus importante que le pipeline est plus long.
A partir du Pentium, une unité de prédiction de branchement, s'attache à évaluer la suite d'instructions qui sera la plus probable. Lors des tests conditionnels, elle mémorise le résultat du test pour en tenir compte au passage suivant selon des algorithmes qui au fil de l'évolution des processeurs devient de plus en plus élaborés. Cette méthode est efficace notamment pour les tâches répétitives exécutées par des boucles de programme.
Hyper-Threading
L'hyperthreading est une technique qui consiste à permettre l'exécution simultanée de plusieurs threads. On traduit généralement le terme thread par « fils d'exécution » ou « sous processus ». Il s'agit d'une partie d'un processus dont l'exécution peut être indépendante du reste de l'application. Le correcteur orthographique d'un traitement de texte en est l'exemple le plus facile à imaginer.
L'HTT Hyper-Threading Technology est apparu chez Intel avec le Pentium Xeon, il est disponible sur les Pentium 4 qui tournent à au moins 3,6 GHz. L'hyperthreading était selon la rumeur présent dans les premiers Pentium 4 mais Intel l'aurait par prudence mi hors d'usage avant d'être absolument sûr de son bon fonctionnement.
On ne peut tirer avantage de l'hyperthreading que si les applications, le système d'exploitation, le processeur le BIOS et le Chipset sont prévus pour.
Certains éléments du processeur qui caractérisent son état sont dédoublés de sorte à émuler deux processeurs logiques au sein d'un seul cœur.
L'hyper-threading permet l'exécution concurrente de deux jeux d'instructions afin d'éviter certains temps morts.
Ces temps morts sont par exemple dus à l'absence d'une donnée utile dans la cache (cache miss) ou à une
erreur de prédiction de branchement qui annihile la séquence d'instructions entamée dans le pipeline.
Le processeur physique agit alors comme deux processeurs virtuels aussi dits "processeurs logiques" qui
apparaissent dans le gestionnaire de périphérique comme deux processeurs distincts.
Le gain de performance annoncé par Intel va actuellement jusqu'à 30%.
Il est optimum quand les logiciels sont développés dans l'optique de l'Hyper-Threading.
Plus de précisions à ce sujet : Introduction to Multithreading, Superthreading and Hyperthreading
Processeurs multi-cœurs
Une autre manière de favoriser l'exécution simultanée de plusieurs processus ou de plusieurs threads est de placer plusieurs processeurs, on dira plusieurs cœurs, dans le même boîtier. Cette technique convient particulièrement au multitâche puisqu'avec elle, il y a réellement autant de tâches qui peuvent s'exécuter en parallèle que de cœurs dans le processeur. Les applications pour bénéficier pleinement du multi-cœur doivent avoir été repensées pour pouvoir se subdiviser en tâches parallèles.
Liens recommandés
- How Microprocessors Work
- Unité Centrale de Traitement - Architecture et fonctionnement (Introduction + Figure 1)

